
Page 49 - 无损检测2023年第二期
P. 49
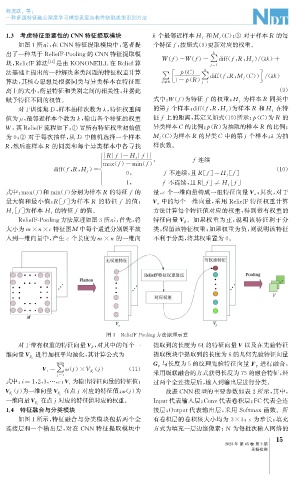
程虎跃, 等:
一种多源特征融合深度学习模型及复杂构件缺陷类型识别方法
1.3 考虑特征重要性的 CNN 特征提取模块 k 个最邻近样本 H j 和M j C ); ③ 对于样本R 的每
(
如图1所示, 在 CNN 特征提取模块中, 笔者提 个特征 , 按照式( 9 ) 更新对应的权重。
f
出了一种基于 ReliefF-Poolin g 的 CNN 特征提取模 k
f =
W ( ) W ( ) ∑ f )/( λk ) +
f -
块, ReliefF算法 [ 12 ] 是由 KONONEILL 在 Relief算 diff ( , R , H j
j = 1
法基础上提出的一种解决多类问题的特征权重计算 p C ) k , (
(
∑
∑
(
算法, 其核心思想是根据同类与异类样本在特征距 C≠ R 1-p R ) difff R , M j C ) /( λk )
j = 1
离上的大小, 衡量特征和类别之间的相关性, 并据此 ( 9 )
f
赋予特征不同的权值。 式中: W ( ) 为特征 f 的权重; H j 为样本R 同类中
对于训练集 D , 样本抽样次数为λ , 特征权重阈 的第 个样本; diff ( , R , H j ) 为样本R 和 H j 在特
j
f
值为 , 最邻近样本个数为k , 输出各个特征的权重 征 f 上的距离, 其定义如式( 10 ) 所示; ( C ) 为 R 的
p
μ
W , 其 ReliefF流程如下: ① 置所有特征权重初始值 异类样本C 的比例; ( R ) 为抽取的样本R 的比例;
p
为0 ; ② 对于每次抽样, 从 D 中随机选择一个样本 M j C ) 为样本R 的异类C 中的第 j 个样本; λ 为抽
(
R , 然后在样本R 的同类和每个异类样本中各寻找 样次数。
f -H j f
R [ ] [ ]
, f 连续
f -min ( )
max ( ) f
f
diff ( , R , H j = ( 10 )
f =H j f
0 , f 不连续, 且R [ ] [ ]
[ ]
1 , f 不连续, 且R [ ] H j f
f ≠
)
式中: max ( ) 和 min ( ) 分别为样本R 的特征 f 的 量, c 个一维向量构成一组特征向量V α ; 其次, 对于
f
f
最大值和最小值; R [ ] 为样本 R 的特征 f 的值; V α 中的每个一维向量, 采用 ReliefF 特征权重计算
f
H j f 的特征 f 的值。 方法计算每个特征值对应的权重, 得到带有权重的
[ ] 为样本 H j
ReliefF-Poolin g 方法原理如图3所示, 首先, 将 特征向量V β 。如果权重为正, 说明该特征利于分
大小为 m× n× c特征图M 中每个通道分别展平放 类, 保留该特征权重; 如果权重为负, 则说明该特征
入到一维向量中, 产生c 个长度为m ×n 的一维向 不利于分类, 将其权重置为0 。
图3 ReliefF-Poolin g 方法原理示意
, 对其中的每个一 提取到的长度为64的特征向量V 以及在先验特征
对于带有权重的特征向量V β
进行加权平均池化, 其计算公式为 提取模块中提取到的长度为6的几何先验特征向量
维向量V β i
m× n 进行融合,
G p 与长度为5的纹理先验特征向量 F p
V i= ∑ ω () V β i () ( 11 ) 采用级联融合的方式获得长度为75的融合特征, 经
j ×
j
j = 1
为输出特征向量的特征值;
式中: i =1 , 2 , 3 ,…, c ; V i 过两个全连接层后, 输入到输出层进行分类。
j 在点 j 对应的特征值; ω () 为 改进 CNN 模型的主要参数如表2所示, 其中,
j
V β i () 为一维向量V β i
在点 对应的特征值对应的权重。 In p ut 代表输入层; Conv代表卷积层; FC 代表全连
j
一维向量 V β i
1.4 特征融合与分类模块 接层; Out p ut代表输出层, 采用 Softmax 函数。所
如图1所示, 特征融合与分类模块包括两个全 有卷积层的卷积核大小均为 3×3 ; s 为步长; 填充
连接层和一个输出层, 对在 CNN 特征提取模块中 方式为填充一层边缘像素; N 为每批次输入网络的
5
1
2023年 第45卷 第2期
无损检测