
Page 67 - 2023中国无损检测年度报告
P. 67
2023 ࠛ௨ចय़ˮڥQGWખ˘ᛸˡԾࡰᤠቅ ࠛ௨ចय़ˮڥQGWખ˘ᛸˡԾࡰᤠቅ 2023
⚥㕂偽䰀唬崵䎃䏞䫣デ ⚥㕂偽䰀唬崵䎃䏞䫣デ
2.2 缺陷检测识别技术 标,并确认其类别和位置,是计算机视觉领域的
2.2.1 数据增强 核心问题之一。
缺陷识别高准确率的实现需要依靠大量图像 传统目标检测算法包括区域选择、特征提取
数据作为支撑。然而,在工程实际中,充足的图 和体征分类,其计算复杂,鲁棒性较低。随着深
像数据往往很难获取,且数据收集过程耗时费力。 度学习技术发展,神经网络的大量参数可以从图
数据增强技术可有效增加训练样本数量、提升数 像中提取鲁棒性、语义性更好的特征,且分类器
据质量和多样性,是解决数据不足问题的重要途 性能更为优越。
径,已成为智能识别领域的必要组成部分。 基于深度学习的目标检测算法主要分为
图像数据增强操作一般在对图像进行必要的 两 类: 一 类是 Two-stage 网 络 模 型,先 进 行
预处理后进行。数据增强算法主要包括无模型、 Region Proposal 区域(RP)生成,再通过卷
基于模型和基于优化策略 3 类方法。 积神经网络进行样本分类,常用的算法有R-CNN、
SPP-Net、Fast R-CNN、Faster R-CNN 和
无模型图像增强是不依赖于任何先验模型的
数据增强,是应用最为广泛的图像增强技术,可 R-FCN 等;另一类则是 One-stage 网络模型,
包括单图像和多图像两个分支。单图像增强是针 直接在卷积神经网络中提取特征来预测目标的
分类和位置,常用的算法有 SSD、YOLO、
对单个图像采用一系列变换生成视觉上不同但语
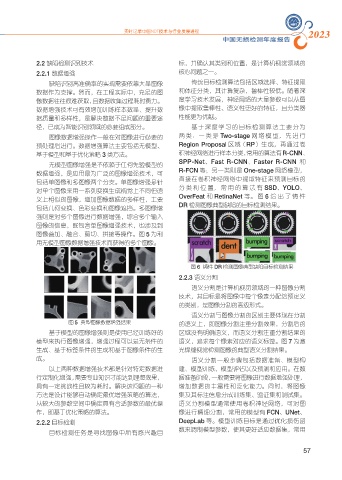
义上相似的图像,增加图像数据的多样性,主要 OverFeat 和 RetinaNet 等。 图 6 给出了铸件
包括几何变换、色彩变换和图像遮挡。多图像增 DR 检测图像典型缺陷的目标检测结果。
强则是对多个图像进行数据增强,综合多个输入
图像的信息,既包含单图像增强技术,也涉及到
图像叠加、融合、剪切、拼接等操作。图 5 为利
用无模型图像数据增强技术而获得的多个图像。
图 6 铸件 DR 检测图像典型缺陷目标检测结果
2.2.3 语义分割
语义分割是计算机视觉领域的一种图像分割
技术,其目标是将图像中每个像素分配给预定义
的类别,是图像分割的高级形式。
语义分割与图像分割的区别主要体现在分割
图 5 典型图像数据增强结果 的语义上,即图像分割注重分割效果,分割后的
基于模型的图像增强则是使用已经训练好的 区域没有明确语义,而语义分割注重分割结果的
模型来执行图像增强,增强过程可以是无条件的 语义,追求每个像素对应的语义标签。图 7 为激
生成、基于标签条件的生成和基于图像条件的生 光焊缝视觉检测图像的典型语义分割结果。
成。 语义分割一般步骤包括数据准备、模型构
以上两种数据增强技术都是针对特定数据进 建、模型训练、模型评估以及预测和应用。在数
行定制化增强,需要专业知识才能达到理想效果, 据准备阶段,一般需要将图像进行数据增强处理,
具有一定挑战性且较为耗时。解决该问题的一种 增加数据的丰富性和泛化能力。同时,将图像
方法是设计能够自动确定最优增强策略的算法, 集及其标注信息分成训练集、验证集和测试集。
从较大的参数空间中确定具有合适参数的最优操 语义分割模型通常使用卷积神经网络,可对图
作,即基于优化策略的算法。 像进行精细分割,常用的模型有 FCN、UNet、
2.2.2 目标检测 DeepLab 等。模型训练目标是通过优化损伤函
数来调制模型参数,使其更好适应数据集,常用
目标检测任务是寻找图像中所有感兴趣目
57